Unsupervised learning
- What Is Unsupervised Learning
- How Unsupervised Learning Works
- Clustering vs Dimensionality Reduction
- Main Algorithms
- Applications
- The Future of Unsupervised Learning
- FAQ
What is Unsupervised Learning
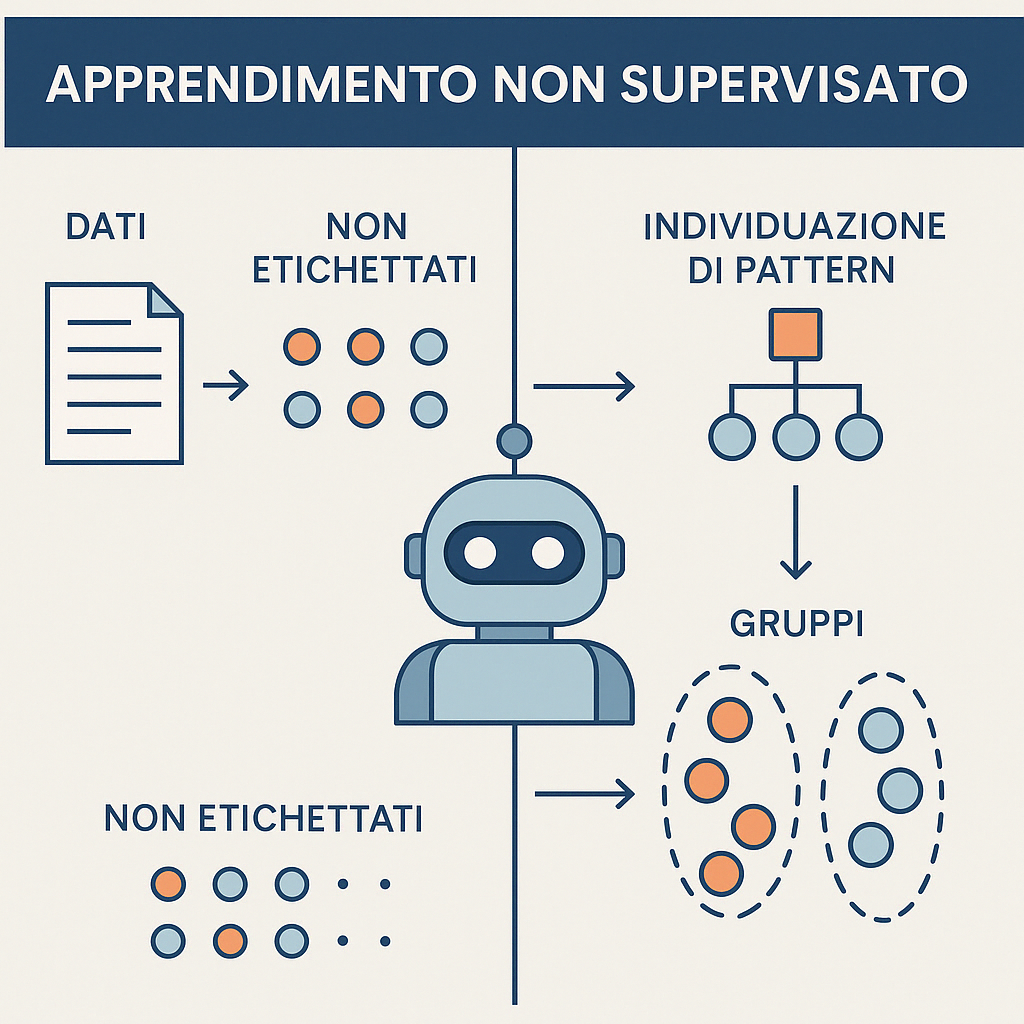
Unsupervised learning is a machine-learning technique in which an algorithm analyses data without labels or predefined outputs. The goal is to uncover hidden structures, correlations, and patterns without the system having prior knowledge of how the data should be classified. It is particularly useful when labels are unavailable or when you want to explore data without pre-conceptions. This approach is used when data cannot be labelled, or when you wish to verify whether natural patterns, clusters, or groupings—often invisible to the human eye—exist. In short, you “let the data speak for themselves,” enabling the algorithm to highlight similarities, anomalies, or trends.How Unsupervised Learning Works
Unsupervised learning typically involves several fundamental steps:- Data collection: obtain a dataset with no labels.
- Data pre-processing: normalisation, cleaning, and format handling.
- Algorithm selection: choose a clustering or dimensionality-reduction technique that fits the analysis goal.
- Pattern identification: the algorithm analyses the dataset to extract common groups or features.
- Result interpretation: examine the outputs to understand the hidden information in the data.
Clustering vs Dimensionality Reduction
Unsupervised learning is mainly divided into two categories: a) ClusteringClustering groups together similar data points. The algorithm looks for “natural” segments in the dataset based on distance or similarity metrics. Typical use-cases include:
- Customer segmentation in marketing.
- Anomaly detection in financial data.
- Identification of genetic groups in biology.
Dimensionality reduction simplifies high-dimensional datasets while preserving the essence of the information. Typical use-cases include:
- Data compression to speed up computation.
- Visualising multidimensional data in 2D or 3D.
- Removing noise and irrelevant variables.
Key algorithms
Several core unsupervised-learning algorithms include:- K-Means: a clustering algorithm that partitions data into k groups based on similarity.
- DBSCAN: density-based clustering useful for identifying groups with differing densities.
- PCA (Principal Component Analysis): a dimensionality-reduction method that preserves as much variance as possible.
- Autoencoders: neural networks that reconstruct data in a more compact form, useful for feature extraction or anomaly detection.
Applications
- Healthcare: analysing genetic and diagnostic data to identify patient sub-groups or related diseases.
- Cybersecurity: detecting anomalous network behaviour to prevent attacks.
- E-commerce: personalising product recommendations based on purchasing patterns.
- Manufacturing: monitoring quality and identifying anomalies in production processes.
The Future of Unsupervised Learning
Unsupervised learning is a core machine-learning technique that analyses complex data without predefined labels. Thanks to its flexibility, it can reveal hidden patterns and improve strategic decision-making across many fields. As AI technologies advance, unsupervised learning will become more sophisticated, increasingly blending with supervised and reinforcement methods to produce richer, smarter models. Although it faces challenges—such as interpretation difficulty and evaluation—it will grow in importance as data volumes explode and businesses seek value even from unlabeled information.FAQ
What does “unsupervised learning” mean?
Unsupervised learning is a machine-learning paradigm in which the algorithm receives data without labels (outputs) and autonomously identifies patterns, groups or latent representations that describe the dataset’s internal structure.
What is the key difference between supervised and unsupervised learning in AI?
In supervised learning the model has labelled examples and learns to map inputs to outputs for prediction. In unsupervised learning there are no labels; the goal is not to predict but to uncover hidden structure (clusters, correlations, rules) in the data.
What characterises semi-supervised learning?
It leverages a small set of labelled data together with a large amount of unlabelled data, lowering labelling costs and improving generalisation through techniques such as pseudo-labelling or consistency regularisation.
Unsupervised learning examples
- Customer clustering with k-means to segment a market.
- Dimensionality reduction with PCA or t-SNE to visualise complex data.
- Association rules (market-basket analysis) to suggest complementary products.
- Anomaly detection to spot fraud or equipment failure.
- Autoencoders for image denoising or compression.
What is reinforcement learning?
In reinforcement learning an agent interacts with an environment, takes actions and receives rewards or penalties. It learns a policy that maximises cumulative reward over time; applications include robotics, strategic games (e.g., AlphaGo) and control systems.