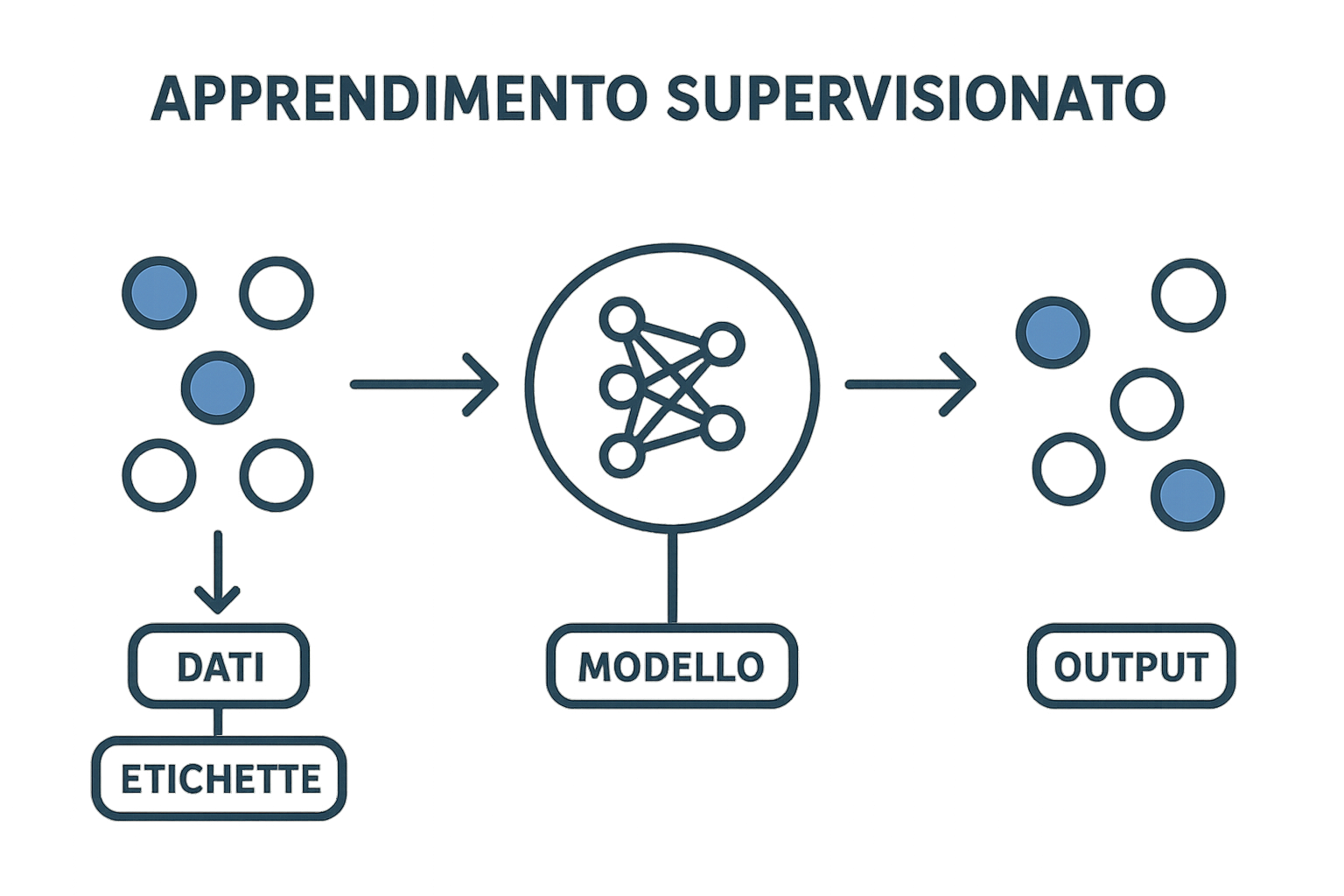
Supervised learning is one of the fundamental techniques in machine learning.
In this article you’ll discover how it works, when it is used, and which leading algorithms make it so powerful.
Supervised learning is one of the central paradigms in machine learning and a fundamental
methodology in artificial intelligence.
In this context, an algorithm is trained on a labelled data-set: every example in the data
has a corresponding label or “correct answer.” The algorithm learns the relationship
between inputs (features) and outputs (expected results), developing a model that can
predict on new data. This differs from unsupervised learning, where explicit labels are
missing.
The process relies on the input–output relationship: the algorithm aims to generalise from
the provided examples, so it can handle previously unseen cases correctly. The end result
of training is a predictive model capable of mapping unknown inputs to estimated outputs
with a certain accuracy.
How Supervised Learning Works
Supervised learning typically unfolds in several stages:
Data collection: start with a data-set that already contains labels.
Pre-processing: clean and transform the data (e.g. normalisation, outlier removal).
Data split: usually divide into training set (about 80 %), validation set (10 %), and test set (10 %).
Algorithm selection: pick an algorithm suited to the task—linear regression, decision tree, neural network, etc.
Training: “train” the model on the training set, tuning with the validation set to avoid over-fitting.
Evaluation: test the model on unseen data (test set) to measure its accuracy.
The objective is to minimise the difference between the model’s predictions and the actual
labels, producing a model that generalises well rather than merely memorising the training data.
Types of Supervised Learning
There are two main categories of supervised learning:a) Classification
In classification, the algorithm learns to recognise which category a data point belongs to. Applications range from image recognition (faces, objects) and email spam filters to medical diagnosis (identifying cancerous cells).b) Regression
Regression focuses on predicting a continuous numerical value (e.g., a house price). The model learns the relationship between a set of features and a target value, such as market value, energy demand or economic trends.
Supervised-Learning Algorithms
Linear Regression – predicts a numeric value based on a linear relationship.
Decision Trees – split data using hierarchical rules to reach a decision.
Support Vector Machines (SVM) – find the optimal boundary to separate data into distinct groups.
K-Nearest Neighbours (KNN) – classifies a new data point according to its closest “neighbours.”
Artificial Neural Networks – inspired by the human brain, effective for complex tasks such as speech or image recognition.
Advantages and Disadvantages of Supervised Learning
Advantages
High accuracy: thanks to labelled data, supervised models tend to give precise predictions.
Interpretability: models such as linear regression or decision trees are easy to understand.
Wide applicability: from medicine to economics, supervised learning is used in numerous sectors.
Disadvantages
Dependence on labelled data: obtaining accurately labelled data-sets can be costly.
Possible over-fitting: overly complex models risk “memorising” the training data without generalising.
Limited adaptability: if the training data don’t cover new situations, the model may struggle to adapt.
The Future of Supervised Learning
Supervised learning remains a cornerstone technique for building predictive models from labelled data. Even with the rise of other approaches—unsupervised, reinforcement and semi-supervised methods—it continues to play a central role.Current research aims to reduce dependence on labels by developing methods that let models learn from fewer “guided” examples or in a self-supervised fashion. In addition, combining supervised techniques with unsupervised and reinforcement learning could yield systems that are even more autonomous and adaptable.In short, supervised learning will stay a key tool in AI: its robustness and methodological clarity make it one of the most reliable paradigms for solving real-world problems—from image classification to numeric forecasting that drives business strategy.
Autore
Nicolò Caiti
Ho fatto del MarTech il mio lavoro. Mi occupo di intelligenza artificiale applicata al marketing digitale. In questo blog, analizzo come l’AI sta trasformando il settore: migliorando le performance web, ottimizzando le strategie digitali e velocizzando il lavoro di tutti. Con anni di esperienza nell’automazione del marketing e nella gestione di customer journey avanzati, condivido insight pratici, case study e best practice per aiutare tutte le persone a sfruttare al meglio le potenzialità dell’AI nel proprio lavoro.
Spero che tu possa trovare le risposte che cerchi!